

Das chinesische KI-Startup DeepSeek hat eine Vorschau seiner neuen Sprachmodellreihe veröffentlicht. Das Flaggschiffmodell V4-Pro übertraf Claude Opus 4.6 und GPT-5.4 und ist damit das beste offene System.
🚀 DeepSeek-V4 Preview ist offiziell veröffentlicht und Open Source! Willkommen im Zeitalter des für 1 Million Token zugänglichen Kontextes.
🔹 DeepSeek-V4-Pro: 1,6 Billionen Parameter insgesamt / 49 Milliarden aktive Parameter. Leistung auf dem Niveau der weltweit führenden Closed-Loop-Modelle.
🔹 DeepSeek-V4-Flash: 284 Milliarden insgesamt / 13 Milliarden aktive Parameter.… pic.twitter.com/n1AgwMIymu– DeepSeek (@deepseek_ai) 24. April 2026
Architektur und Maßstab
V4-Pro verfügt über rund 1,6 Billionen Parameter, von denen jedoch in jedem Schritt nur 49 Milliarden aktiviert werden. In der zweiten Version – V4-Flash – beträgt der Gesamtumfang 284 Milliarden, von denen 13 Milliarden aktiviert sind.
Beide Modelle basieren auf einer Mixture-of-Experts-Architektur (MoE): Bei der Verarbeitung jedes Tokens wird nur der jeweils relevante Teil der Subnetzwerke aktiviert. Dieser Ansatz ist kostengünstiger als vollständig dichte Architekturen, steht ihnen aber in puncto Leistung in nichts nach.
Das anfängliche Training erfolgte anhand eines Korpus von über 32 Billionen Token. Anschließend trainierten die Entwickler die Modelle schrittweise und wiesen separate Blöcke für Codierung, Mathematik, Logik und die Ausführung von Anweisungen zu. Die finale Version vereint diese Fähigkeiten durch Destillation.
Der lange Kontext ist günstiger geworden.
Der Hauptunterschied in V4 lag in der Optimierung der Verarbeitung langer Sequenzen. Das Kontextfenster mit 1 Million Token ist zwar auch in anderen Modellen verfügbar, seine Verwendung ist jedoch üblicherweise mit hohen Kosten und Latenzzeiten verbunden.
DeepSeek gab an, dass die neue Version den Ressourcenverbrauch solcher Operationen deutlich reduziert hat. Im Vergleich zu V3.2 benötigt V4-Pro bei maximaler Kontextnutzung etwa 27 % weniger Rechenleistung und 10 % weniger KV-Cache- Speicher. Bei V4-Flash liegen die entsprechenden Werte bei etwa 10 % bzw. 7 %.
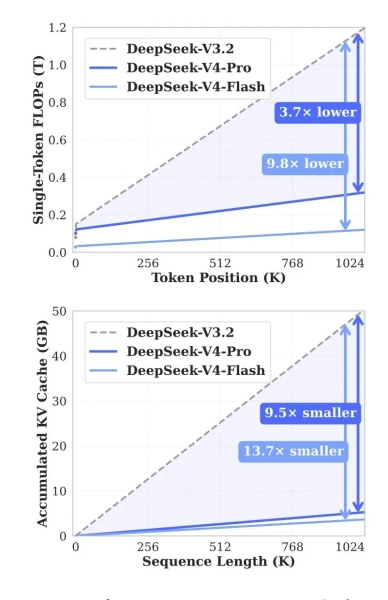
Quelle: Hugging Face.
Das Team erzielte dieses Ergebnis durch eine hybride Aufmerksamkeitsarchitektur: Zwei Mechanismen komprimieren Daten und reduzieren den Arbeitsaufwand bei der Verarbeitung langer Texte. Zudem werden spezielle Hyperlinks für Stabilität und der Muon-Optimierer zur Beschleunigung des Lernprozesses eingesetzt.
Denkweisen und Handlungsfähigkeiten
DeepSeek V4 unterstützt drei Schlussfolgerungsmodi:
- Unreflektiert – schnelle Antworten auf einfache Fragen ohne zusätzliche Analyse.
- Think High – tiefgreifende Analysen für komplexe Aufgaben und Planung.
- Think Max – Maximalmodus: Das Modell durchläuft jeden Schritt und prüft alle Optionen.
Im Max-Modus bleiben bei Agentenaufgaben nun die Zwischenschritte innerhalb einer einzelnen Aufgabe erhalten. In der vorherigen Version ging ein Teil dieses Kontextes bei der Benutzerinteraktion verloren.
Testergebnisse
Laut DeepSeek erzielt die Flaggschiffversion in einer Reihe von Bereichen Ergebnisse, die mit führenden Systemen vergleichbar sind:
- Bei Programmieraufgaben auf Codeforces erreichte das Modell eine Bewertung von 3206 – Platz 23 unter den aktiven Programmierern der Welt, gleichauf mit GPT-5.4;
- Im Fach Mathematik erzielte sie 95,2 Punkte im HMMT 2026 und 89,8 Punkte im IMOAnswerBench und lag damit vor den meisten Konkurrenten.
- SimpleQA-verifiziertes Wissen – 57,9 (Opus 4.6 – 46,2, aber Gemini 3.1 Pro – 75,6).
- In Bezug auf die Argumentation liegen die Modelle nur drei bis sechs Monate hinter GPT-5.4 und Gemini 3.1 Pro zurück;
- Im internen DeepSeek-Test, der Entwicklung, Debugging und Refactoring umfasste, erreichte das Modell 67 % – zwischen Sonnet 4.5 (47 %) und Opus 4.5 (70 %).
- In Agentenszenarien und Entwicklungsaufgaben erzielte V4-Pro-Max 80,6 % bei SWE Verified und 67,9 % bei Terminal Bench.
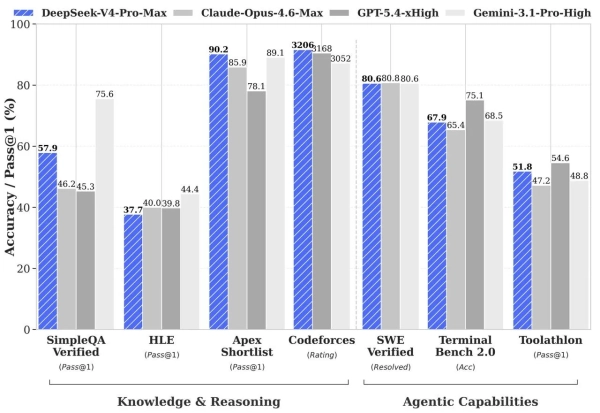
Quelle: Hugging Face.
V4 wurde speziell für reale Szenarien geschult: Datenanalyse, Berichtserstellung, Dokumentenbearbeitung und Internetrecherche mit iterativer Anwendung von Tools.
Um die Eignung des Modells für die praktische Entwicklung zu prüfen, führte das Startup interne Tests anhand der Aufgaben seiner Ingenieure durch. In einer Umfrage unter 85 Entwicklern und Forschern gaben 52 % an, bereit zu sein, V4-Pro als Hauptmodell für die Codierung zu verwenden, und weitere 39 % äußerten sich geneigt, diese Entscheidung zu treffen.
Zur Erinnerung: OpenAI hat GPT-5.5 am 23. April veröffentlicht. Das Modell wird als „eine neue Stufe der Intelligenz für reale Aufgaben und das Agentenmanagement“ positioniert.